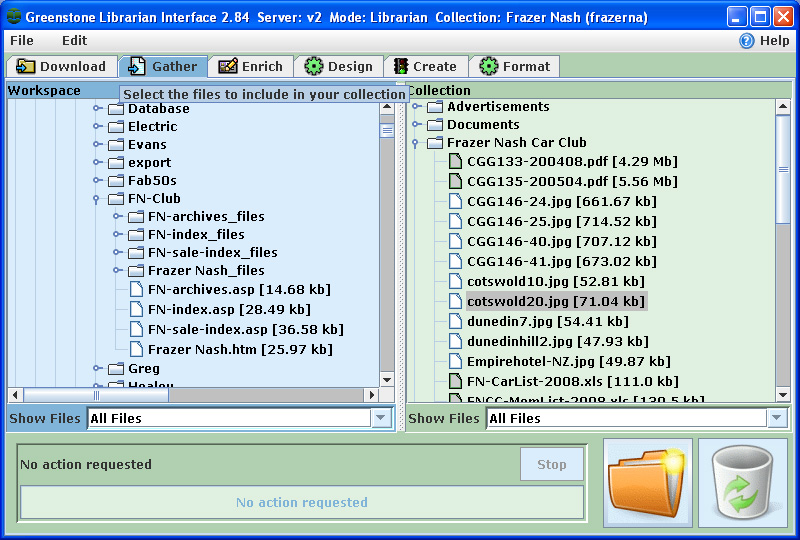
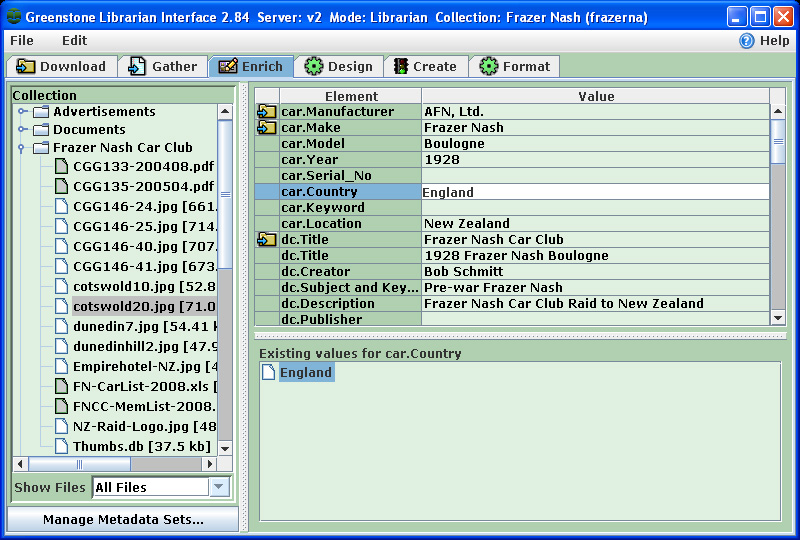
Car Collections: An Organizing Approach
Bob Schmitt
December, 2011
|
Summary: Nearly every car collector, whether he or she has one or hundreds of vehicles, also accumulates a history of the car: photos, documents, books, magazines, videos, etc. directly for the particular car(s) or the marque. Car clubs almost always have list of owners, their cars, former members and owners. Journalists, historians and various organizations involved with competition or exhibitions are greatly interested the "provenance" of a particular car when was it manufactured, what color was it, who owned it when? This is a report on a continuing project to describe using computer software to organize vehicle and owners factual data and related material in traditional and digital formats. Background: Ive long owned a car with a very small production: only 85 were made after WWII. During the first years of ownership, there was very little history available for these cars, so I started a website in 1997 (FrazerNash-USA.com). Over the years, I corresponded with owners, friends of owners and historians who sent me data about these cars and I collected the names of the owners of the Frazer Nash cars which came to the U.S. just 16 cars. This was kept in a spreadsheet, with basic data on all 85 cars. Ive been in contact with the registrar of the postwar Frazer Nash cars and a director of the Frazer Nash archives (UK) since 1997. Three years ago, I thought to improve the spreadsheet technique and work with more complete data. I had a spreadsheet of Frazer Nash Car Club members and their cars with "mostly uniform" data. Some owners had as many as four cars, so the "Car" category was not consistent. Member addresses, especially in the UK, were a challenge to fit in columns/fields! Following recommended database design principles, I created separate "Members/Owners" and "Cars" tables and added "Racing History", "Literature" and "Exhibitions" tables from other sources. I added my data on the US owners of the postwar cars. These were put in a simple Access database which gave the ability to make queries and reports. However I could not link the owners, cars and history because of my Access inexperience, so the project went into limbo and was no help to FN Club record-keeping at that time. Since that time, the Frazer Nash Car Club and Archives started a digitization project, using Club volunteers, to convert Archive and factory records for the prewar cars. Thousands of photographs and other business records remain in "physical" format. I acquired an improved scanner in May, 2011 and started a personal project to review my collection of 5-10,000 photos, slides and negatives dating from 1962. I've long wanted a "system" that would index or classify basic lists of photo groupings, the actual physical images, the resulting digital scans and eventually include the digital images Ive acquired in the last 6 years. And I bought two books on my old Access 2000 program! This Project: After visiting two private vehicle collections in mid-June, I was inspired to revive the FN Car Club (or collectors) database project. My basic approach was to combine the cars/members from the Access database done in 2008 with an "image" or "document management" database/system, preferably open-source software (no cost). I also hoped to find a system to organize my personal photographs. Databases The new goal for the car collection system was to include both "structured" and "unstructured" data that is indexed, organized and searchable through combined databases or an entirely new "system". An example of "structured" data is a traditional mailing list of club members (owners) with basic contact information. A list of cars, with serial numbers, model type, build year etc. can be visualized as "structured". A database is the traditional method of using structured data. In addition to creating reports, mailing lists, etc., a relational database can create "many-to-many" relations that can show, for example, a club member (owner) to have many cars and a car, over time, to have many owners. "Unstructured" data is almost everything else! Books, articles, documents, photos, videos. These items may be in files or stored on a computer. They may appear on a list (inventory) now or are in digital format (eventually); it is highly desirable to link them to particular cars and owners. I think a database is an essential first part of organizing data for a car collection. I thought the old FN Club database on Access could be greatly improved and transitioned to an open-source database program, possibly Internet accessible. Photo/Image Management Software To handle the unstructured car collection data, my first research area was with "image management systems". One example is Picasa, which Ive used for several years and have found limited classification of images is possible using albums and tags, but Picasa cannot do anything with images or documents that have not been scanned (digitized). Nearly all other image management software I reviewed was oriented towards professional photographers or towards Internet (webpage) presentation. Document Management Software The next area of research was with document management and enterprise document management systems, thinking these would be inclusive for all types of documents. Although there are many open source systems of this type (see http://en.wikipedia.org/wiki/Document_management_system) and it is potentially a useful software category, these systems have been greatly overshadowed by "content management systems" which are primarily oriented towards managing web content. (see http://downloadpedia.org/Open_Source_Content_Management_Systems). A content management system may be necessary for a car collection with an extensive public website. Joomla is a powerful, open-source software system to create and manage content for a website. Library Management Software Because larger car collections are likely to have a library, my final research area was "library management systems", which I expected to include both paper-based media and digitized media in their scope. I found two library management systems/databases from New Zealand. One, Koha, is fully-featured for the management of an entire library - the catalog, borrowers, acquisitions, etc. It is fairly complicated to implement but is reported to run many libraries already, including a current implementation for all public libraries in Vermont. The other, Greenstone, is oriented to digital media, has a good "librarian interface" and is accessed to "users" by a web browser, either directly or (if server-based), remotely as any other website. Greenstone can also produce a self-running CD or DVD containing the documents of any collection set. These two New Zealand systems, Koha and Greeenstone, are available as an integrated download to a Linux-based CD, which seems to be a plus. I've made that CD, but do not plan to use it. Greenstone looked very promising, even for a personal trial with only my Frazer Nash and other data. Ive gone through a Greenstone tutorials and an on-line workshop. There is much support on the Internet, including from an active development team at Waikato University, Hamilton, New Zealand, where the software originated. Greenstone runs on Windows, Mac and Linux systems. The self-running demonstration CDs or DVDs only run on a Windows operating system. Greenstone - Open Source Software from New Zealand I first installed Greenstone on a IBM Thinkpad T42, a laptop more than five years old. Ive created several separate collections of images and documents and the software works "as advertised". With this experience, I first made a collection which includes Petersen Automotive Museum related material photos from a current exhibit, auto racing periodicals digitized by Bob Norton, and a list of Bill Pollack's video interviews (Excel). Because I personally wanted a system applicable to my slides & negatives that have not been digitized, my trials showed I could put an inventory list of photos and proof sheets (an Excel spreadsheet) in a "Collection" and the text becomes indexed and fully searchable. If an inventory list shows the subject matter and location of photos, slides and negatives, this is very useful for classifying and locating such images that are not yet digitized. The list of Bill Pollack's video interviews thus becomes more accessible and useful. I also found that Bob Norton had made a full 28 page index of the 9 volumes of "MotoRacing" (MotorRacing-Index.pdf) which was text-rich and searchable. This was included in the full word index created by Greenstone. The PDF files of the documents in this collection otherwise are images only, not text-searchable. I ran a OCR program on one page of one copy of MotoRacing and it worked very well, about 95% accuracy. Document scanning is frequently seen as an obstacle to creating a digital library/collection. A flatbed scanner is just one method of digitizing documents; other techniques are available and labor costs have dropped. Scanning may be done directly to PDF files with full-text access. Existing PDF files can be converted to text using OCR; open-source "Qippa" is being tested for this function. I also made a test conversion of a FN club membership list (Excel) to a "comma-delimited" (.cvs) file, which Greenstone then separated into individual records for each member or car. This could be very useful. I also created a second Greenstone "collection" from approximately 100 Frazer Nash images and documents, totaling 140 MB. Greenstone created the CD files in a hard-disc directory, which were copied to a CD. The CD was completely "self-running"; after inserting the DVD in a Windows PC, a web-browser (Firefox) user interface popped up and the images and documents in this collection were fully indexed, searchable, and viewable. I planned to make a stand-alone CD from the "Petersen collection" (sample data), but the 10.3 GB file was too large for a CD or DVD. Next, I used the same Greenstone stand-alone CD function to make "CD files" from the "Petersen collection" and copied the files to a USB-connected hard drive. The collection ran perfectly when connected to an Acer netbook. Later, I deleted some of the images and documents from the sample Petersen collection to reduce the number of items to less than 1,000 and its size to 2.4 GB. A self-running DVD worked "as advertised". Finally, I combined three collections - Petersen, Frazer Nash and a third collection, a set of Fabulous Fifties PDF-format newsletters, on a single DVD. I've distributed this DVD as a sample of Greenstone capabilities. As mentioned above, it only runs on a Windows PC. Using Greenstone The Greenstone implementation and use steps are: 1. Download the Greenstone software from their site. Note that you can choose a Windows, MacOS or Linux version to run on your system. I've downloaded a large file of Greenstone workshop courses and training materials and completed all the lessons of a 4.5 day Workshop - but probably should repeat them! This is a very well-designed course and I learned how to use existing meta-tags, the function I did not understand in Step 3, above. Later I learned how to make new, unique meta-tags. For auto collections, this avoids the confusion of which data to put in the standard "subject", "title" etc. categories Now we have new "cars.manufacturer", "cars.make", "cars.year", etc. meta-tags which can be used for direct searches or displays of the items with these tags. Greenstone Resources Greenstone has functions to import nearly any type of file, change the web-browser interface appearance and change how the search and browse results are displayed. The Librarian Interface makes this customization "easier" but the program is definitely on the "techie" side. Greenstone is extremely robust; see the examples of completed Collections at http://www.greenstone.org/examples The largest collection, with a reported 1,000,000+ images, is an extensive archive of New Zealand newspapers, both as images and full text. In addition to Greenstone online training resources, the Greenstone developers authored a book: "How to Build a Digital Library" (second edition), available from Amazon. Preview pages from Amazon show that it includes much useful, general material on library creation, such as international standards, types and uses of metadata/meta-tags. Part 2 of this book is a Greenstone tutorial. A similar open-source program, DSpace, was developed by MIT and HP for academic use. The DSpace site shows over 300 institutions using this system, primarily in the U.S. Greenstone has a tutorial to show how to move a digital collection from DSpace to Greenstone and vice-versa. Comparisons of both systems on the Internet confer no advantage to either and note that classification in either collection is well-preserved. Next Steps: Open-source databases using web-based interfaces are common and can be used for structured data. The FN Club data on an Access database has been improved with a query and maintenance user interface. Possibly it can be later transferred to a more capable, open-sourced web-based system. The database status is here. Because Greenstone also uses a web interface, integration of the structured data (in a database) and the unstructured data (in Greenstone) will be explored. Direct links between the two systems from a single search may be possible. A newer version of Greenstone (2.85) extracted meta-tags from digital camera images (EXIF, which show much data, such as a photo's creation date) and documents ("properties") to the collection and were added to the Petersen and Frazer Nash sample data - a new "sample" DVD was made and digital photographs are shown with their original photo date. However, some of these "next steps" may be outside my limited skills! Conclusion/Recommendations: A car collector or the manager of a(ny) collection with a need to organize the data on the vehicles in the collection should: 1. Review the data currently available and create a database from lists of cars, owners, club members. An Excel spreadsheet if a good first step if nothing else has been done. Data that has been structured in an Excel file or almost any database is nearly always easily transported into an improved database system. About the author: I am a car hobbyist and mostly retired from my former occupation as a technology contracts manager (tech-contracts.com). My car hobby is currently centered on a rare car which was restored in Arizona and New Zealand and is currently in the Classic Car Museum in Nelson NZ. (my website for the car is FrazerNash-USA.com). Long before my career in law and contract managements, I completed grad school in Information Science at the University of Hawaii (in the days of punch cards!) However, when a law school opened at UH and I had GI Bill remaining, I took a path away from computers for a long time. I've been involved with several database and scanning projects for contracts with my last three (large corporate) employers; the results did not seem to justify the costs. A few years ago, I began to help Bill Pollack with his video interview project (with people more or less well-known in the car/racing world) for the Petersen Automotive Museum (Los Angeles). Initially I digitized video tapes of Bill's completed interviews and later helped with his new interviews. We now use high-definition video, which I process to create standard DVDs from the hi-def format. Ive also collected and organized the results of a scanning project of '50s-'60s motoring journals done by retired engineer Bob Norton, now deceased. |